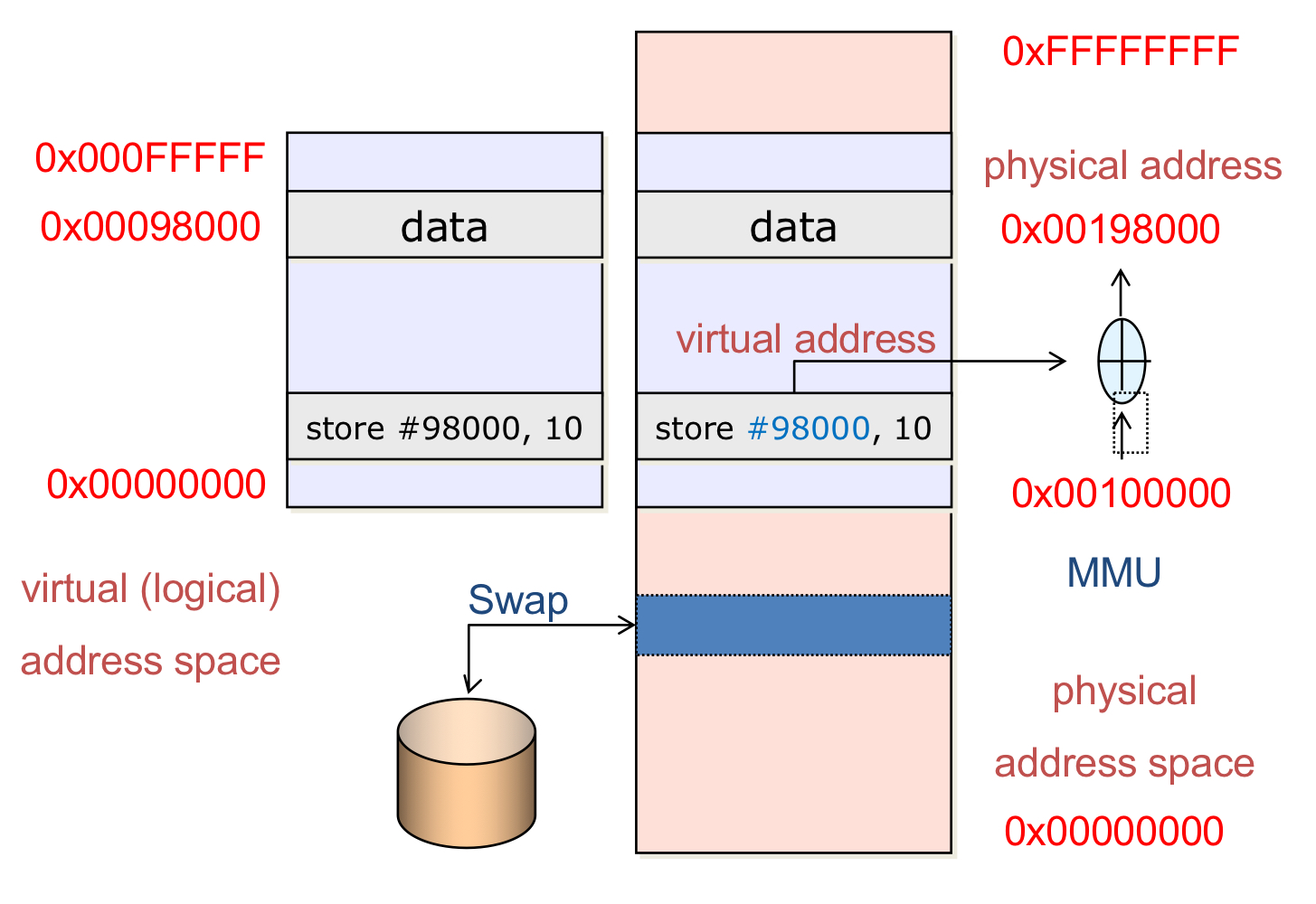
지난 포스팅에서는 logical memory를 physical memory에 할당하고 physical address를 확정하는 시점에 대해 다루었습니다. Compile time, Load time, Execution time 중에서 현재 사용되고 있는 방식은 Execution time 입니다. 프로세스의 코드 라인이 실행이 될 때 logical memory를 physical memory에 할당하고, 이를 참조할 때마다 MMU가 logical address를 physical address로 변환합니다.
그렇다면, logical memory를 physical memory에 어떻게 할당할 수 있을까요?
본 포스팅에서는 logical memory와 physical memory를 mapping 하는 방법에 대해 다룹니다.
Contiguous allocation
logical memory를 physical memory에 연속적으로 할당하는 방식입니다. 각 프로세스는 logical memory를 physical memory에 특정 시작 주소 부터 통째로 할당합니다. physical memory에 여러 프로세스들이 할당되고 해제되면 중간 중간에 빈 Hole 이 생기게 되는데, 이러한 Hole들에 새로운 프로세스를 적재합니다.
Hole에 프로세스를 할당하는 방법은 3가지가 있습니다.
1) First fit: Physical memory를 처음부터 탐색하다가 첫번째로 프로세스의 크기보다 큰 Hole이 등장했을 때 해당 Hole에 프로세스를 할당하는 방법입니다. 프로세스 전체를 탐색하지 않아도 되기 때문에 비교적 overhead가 적습니다.
2) Best fit: Physical memory 전체를 탐색하고, 프로세스의 크기와 가장 비슷한 크기의 Hole에 프로세스를 할당하는 방법입니다. 새로 생성되는 fragment를 최소화 하는 전략으로, 프로세스 전체를 탐색하기 때문에 비교적 overhead가 큽니다.
3) Worst fit: Physical memory 전체를 탐색하고, 가장 큰 크기의 Hole에 프로세스를 할당하는 방법입니다. 새로 생성되는 fragment를 최대화 하여 다음 프로세스를 할당할 자리를 만들겠다는 전략입니다. 프로세수 전체를 탐색하기 때문에 비교적 overhead가 큽니다.
Contiguous allocation 방식을 사용했을 때, MMU는 다음과 같은 방식으로 logical address를 physical address로 변환합니다.
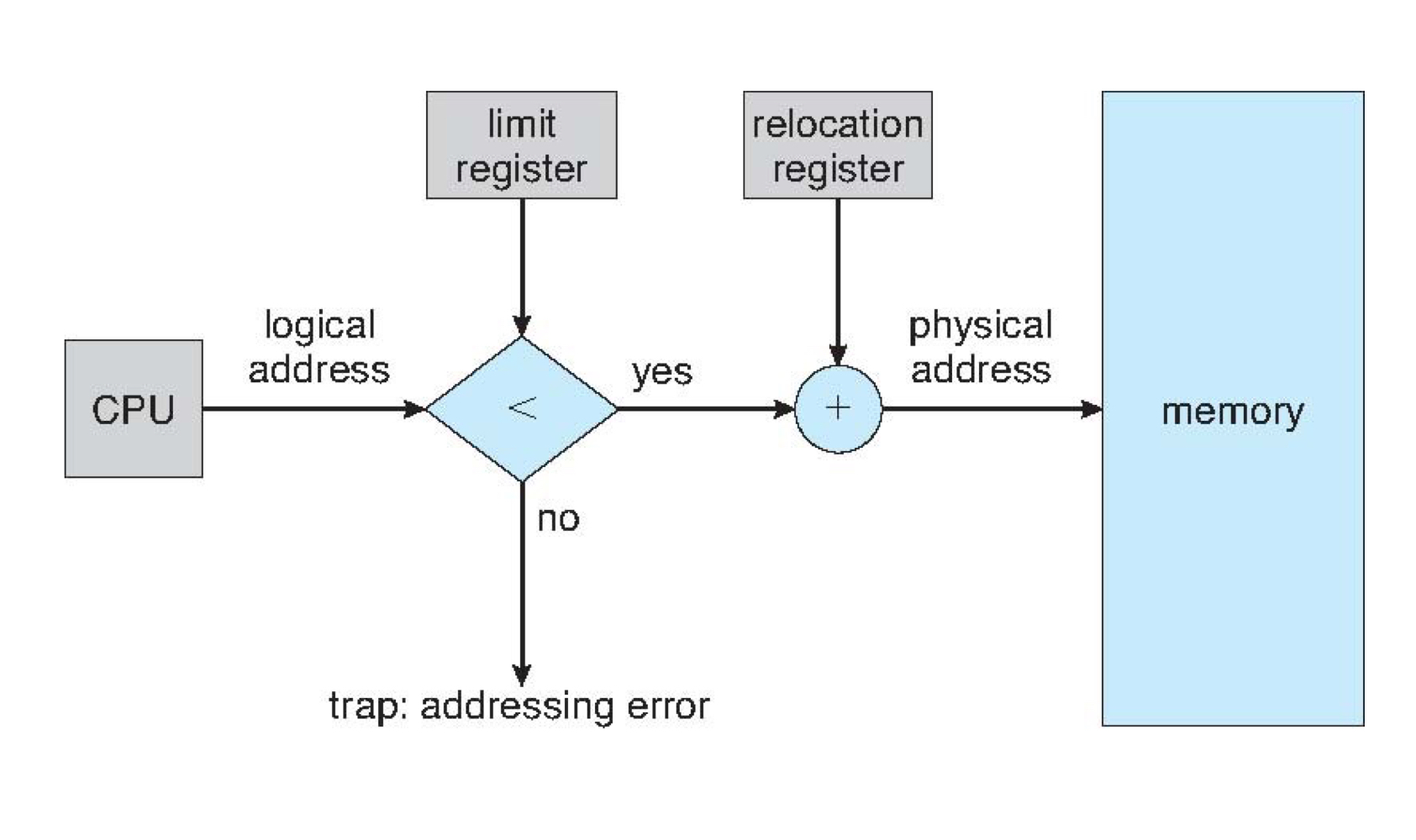
CPU에서 특정 logical address에 접근하라는 명령이 떨어지면, MMU는 limit register를 통해 해당 logical address가 해당 프로세스의 제한 범위를 넘어서는지 확인합니다. 만약 logical address가 limit register를 초과한다면 다른 프로세스의 메모리를 침범한다는 의미이므로 addressing error를 발생시킵니다. 만약 해당 범위를 초과하지 않는다면, logical address에 physical address의 base address인 relocation register를 더하여 physical address를 산출합니다. logical address를 연속적으로 할당했기 때문에 할당이 이루어진 시작 주소만 알 수 있다면 나머지 주소들은 시작 주소를 더한 값이 됩니다.
꽤나 간단한 방법으로 실제 사용할 수 있을 것 같지만, 안타깝게도 Contiguous allocation은 치명적인 단점을 가지고 있습니다. 해당 방법으로 프로세스들을 할당하면 physical memory에 여러 개의 Hole이 생기게 됩니다. Hole 중에는 새로 들어오는 프로세스들과 크기가 맞지 않아 아무 프로세스도 할당이 되지 않는 Hole도 있습니다. 결국 메모리의 낭비가 심해지게 되는데, 이를 External fragment(외부 단편화) 라고 합니다.
Compaction은 External fragment를 해결하기 위한 방법으로, 주기적으로 프로세스들을 secondary storage로 내린 후 다시 정리하여 physical memory로 올리는 방법입니다. I/O가 두번(내리고 올리고) 발생하기 때문에 느리고, Contiguous allocation 은 이론적으로만 존재할 뿐 사용되지 않습니다.
Paging
logical memory를 일정한 크기의 page로 나누고, Physical memory를 page와 동일한 크기의 frame으로 나누어 page와 frame을 mapping 하는 방식입니다. Page 번호를 인덱스로 하는 page table을 두어 mapping된 page와 frame을 기록합니다.
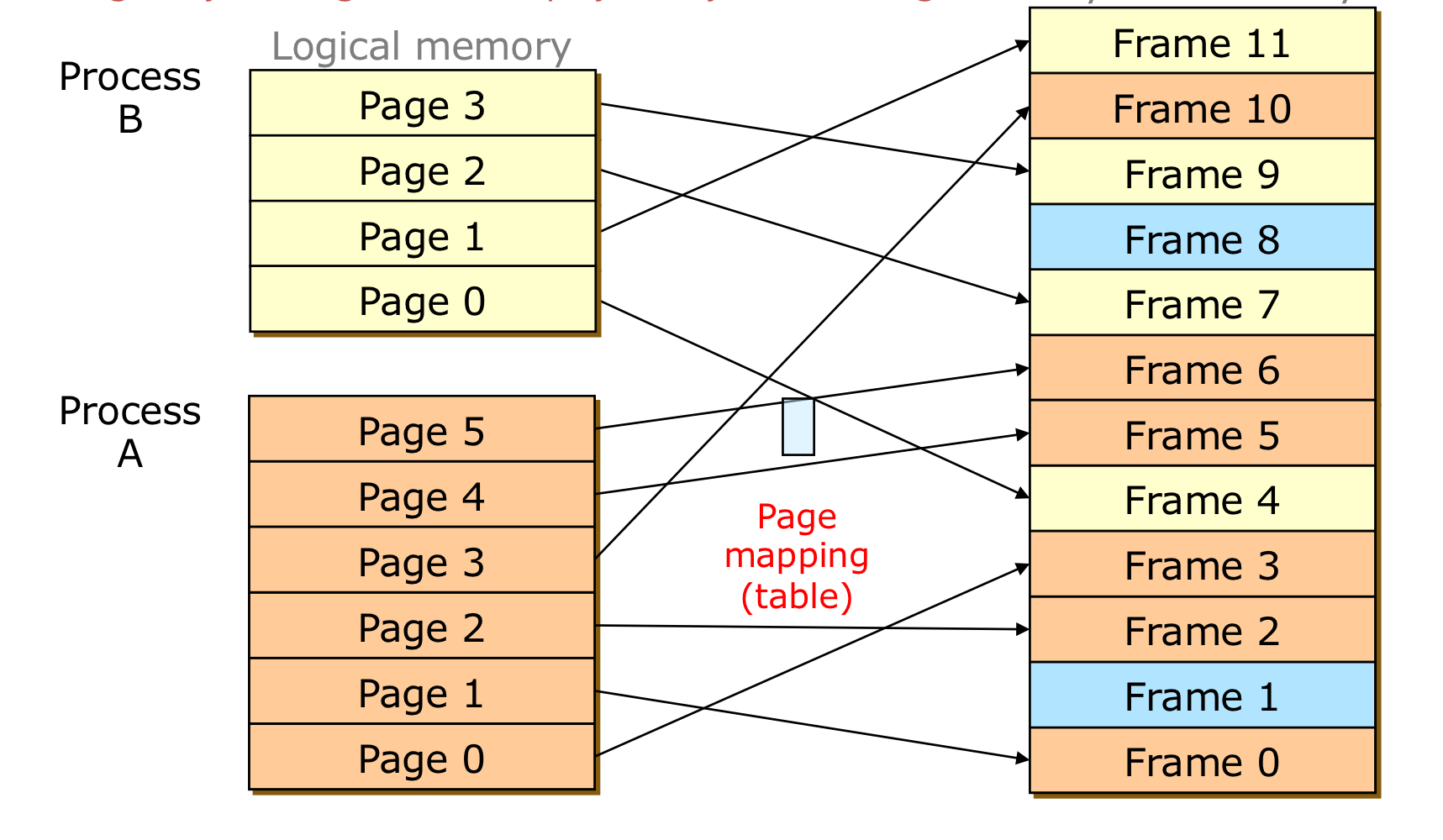
Paging 방식에서 logical address는 (page number, offset) 으로 이루어집니다. offset은 페이지 내에서의 위치로, page number에 상응하는 frame number만 알 수 있다면 해당 frame의 base address에서 offset 만큼 떨어진 주소를 알아낼 수 있게 됩니다. MMU는 page table을 참조하여 page number에 해당하는 frame number를 찾아내고 해당 frame에서 offset 만큼 이동하여 physical memory에 접근합니다.

Paging의 단점은 Internal fragment(내부 단편화)가 일어난다는 것입니다. Internal fragment란, logical memory를 여러 개의 page로 나누었을 때 page 일부가 데이터를 포함하지 않고 비어있어 메모리가 낭비되는 상황을 말합니다. 하지만, 특정 프로세스가 종료되어 Hole이 발생하더라도 다른 page로 mapping 하면 되기 때문에 External fragment가 발생하지 않습니다. Internal fragment는 External fragment보다 메모리 낭비의 양이 적기 때문에 Paging은 현재 메모리 mapping 기법의 기본 토대가 됩니다.
Page Table의 크기
32 bit 의 컴퓨터에서 Page size가 4KB 일 때, 프로세스당 Page table의 크기는 4MB 입니다.
그 이유를 살펴보면,
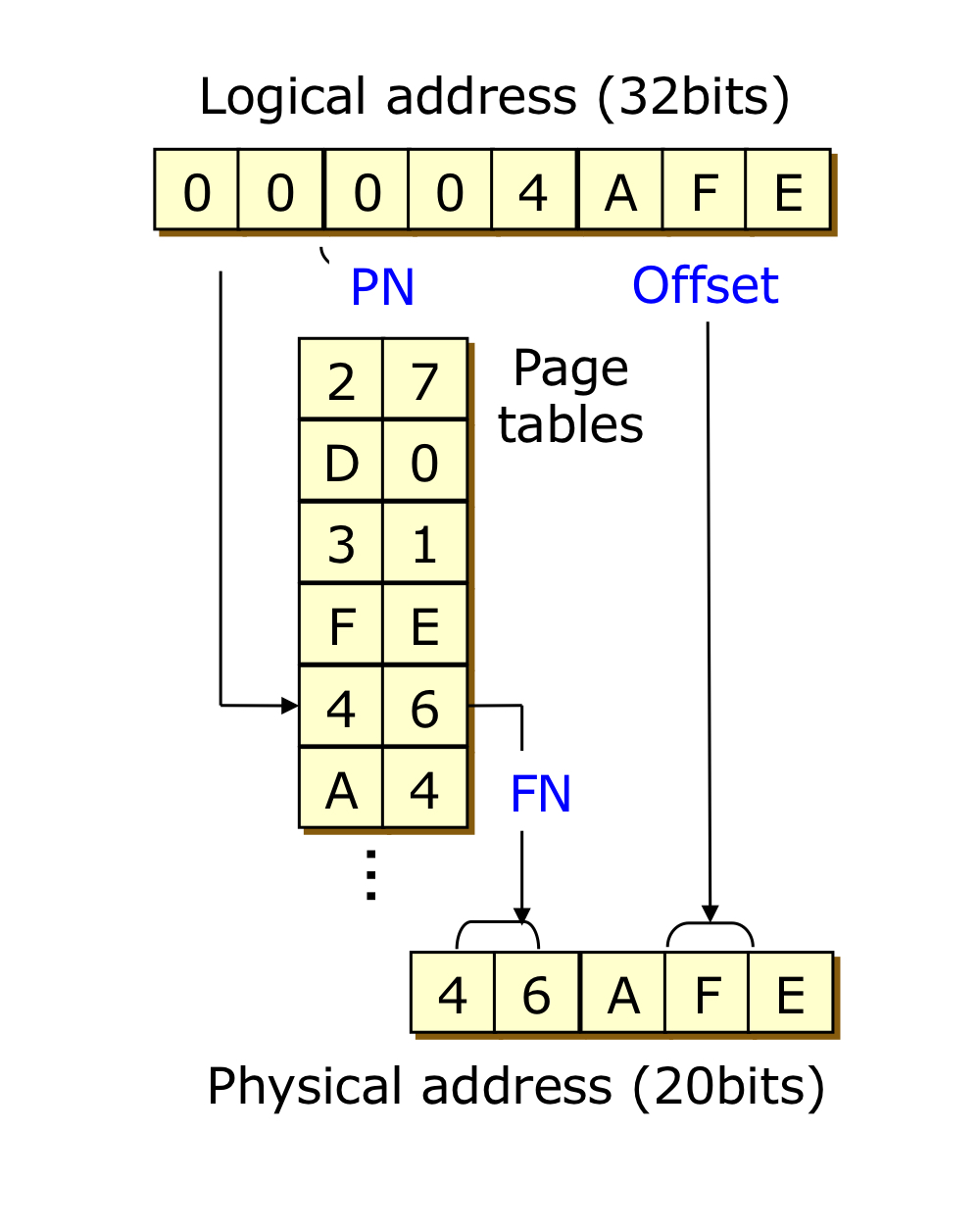
컴퓨터가 32 bit 이므로 logical address는 32 bit로 표현할 수 있습니다. 이 때, Page size가 4KB = 4096bytes = 2^12 bytes 이므로 하나의 page 내부에서 표현되어야 하는 offset 수는 2^12개 입니다. 따라서 전체 32 bit 중에서 12 bit는 offset을 표현하기 위해 사용되어야 합니다.
32 bit에서 offset 12 bit를 빼고 나면, 20 bit가 남습니다. 즉, logical address에서 page number는 2^20 개 만큼 표현이 가능하고, page table의 entry 개수는 2^20개가 됩니다. page table의 한 줄 크기는 32 bit(= 4 bytes) 이므로 프로세스 하나당 page table의 크기는 2^20(entry 수) * 4 bytes(entry 1줄당 메모리 크기) = 4MB 가 됩니다.
TLB를 통한 Page table의 캐싱
Page table의 크기는 매우 크기 때문에 main memory에 저장할 수 밖에 없습니다. Page table을 physical memory에 저장하면 logical memory를 physical memory로 변환하는 과정에서 main memory에 두번(page table 1번, frame number를 파악한 후 데이터에 접근 1번) 접근해야 하기 때문에 overhead가 커집니다. 이러한 문제를 해결하기 위해 TLB라는 것이 사용됩니다.
TLB(Transition Look-aside Buffer)란, 자주 참조될 것으로 예상되는 page number를 MMU 내부에 캐시 형태로 저장하는 것입니다. 한번 참조된 데이터는 다시 참조될 가능성이 높다는 성질을 이용하여 이를 버퍼에 따로 저장해 관리하는 것인데, 이러한 성질을 Locality라고 합니다.
Locality의 종류는 2가지로 다음과 같습니다.
1) Temporal locality: 한번 참조된 데이터는 다시 참조될 가능성이 높다.
2) Spatial locality: 특정 영역이 참조가 되면, 그 인근의 영역도 참조될 가능성이 높다.
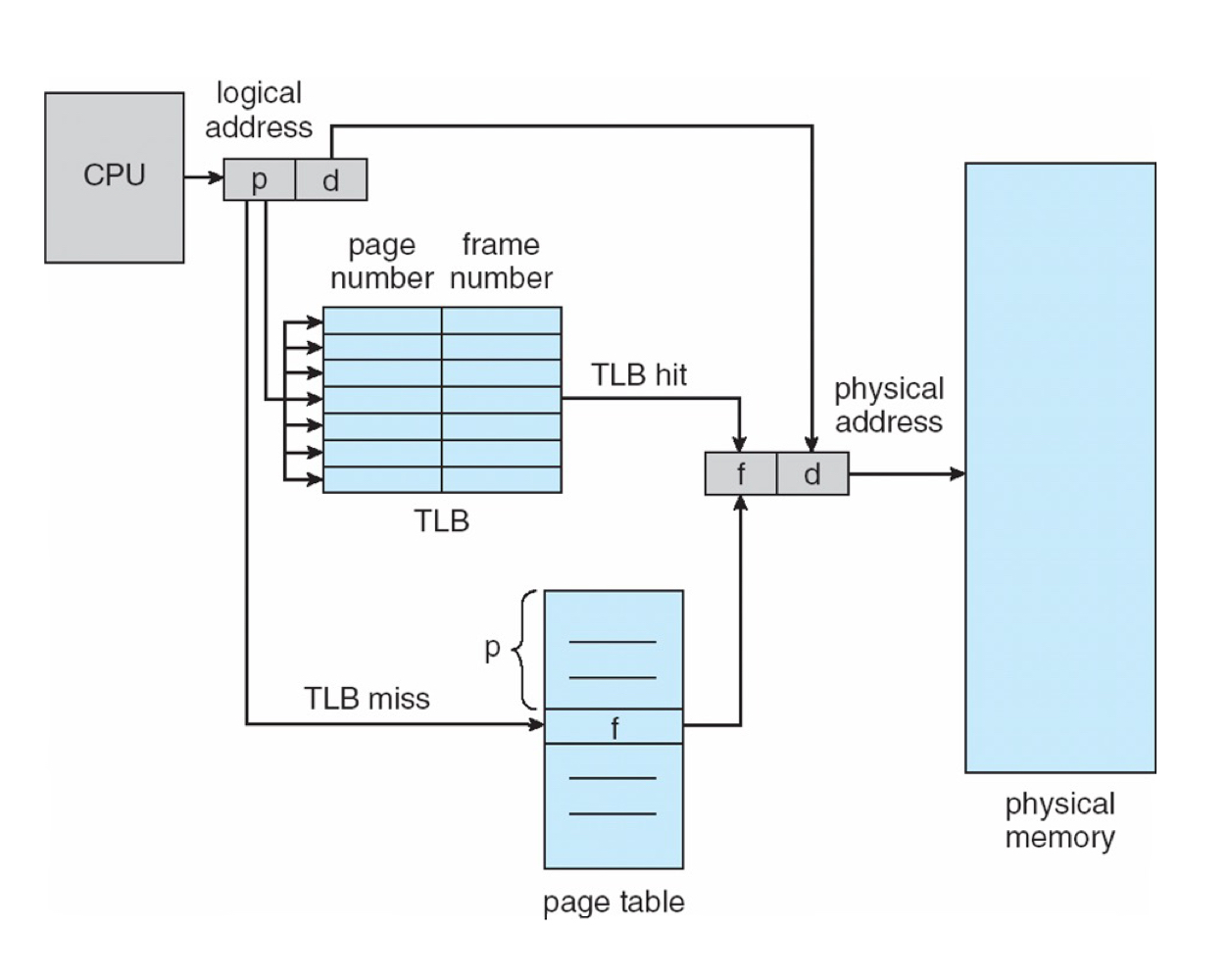
CPU에 logical memory를 참조하라는 명령이 떨어지면, 바로 page table에 접근하지 않고 TLB를 먼저 살핍니다. TLB에 참조하고자 하는 page number에 대한 frame number가 저장되어있다면(TLB hit), 이를 참조하여 바로 physical memory에 접근합니다. 만약, 참조하고자 하는 page number에 대한 frame number가 저장되어있지 않다면(TLB miss) page table에 접근하여 frame number를 알아낸 뒤 physical memory에 접근합니다. 일반적으로, locality에 의해 cache hit rate은 99% 이상이 된다고 합니다.
TLB는 프로세스가 수행된 이후 context switching이 될 때 초기화 되며, 프로세스의 main memory에 대한 위치 register도 함께 수정됩니다.
Page Table의 구조
TLB를 사용하여 캐싱을 하는 것도 좋지만, page table 자체의 크기를 줄이는 방법도 있습니다.
1) Hierarchical Page Tables
logical address를 여러개의 page table로 나누는 방식입니다.
32 bit 컴퓨터, page size = 4KB 인 경우 page table entry는 2^20개가 됩니다. 2^20개의 logical address는 2^10개의 outer page table과 2^10의 inner page table로 쪼갤 수 있습니다.
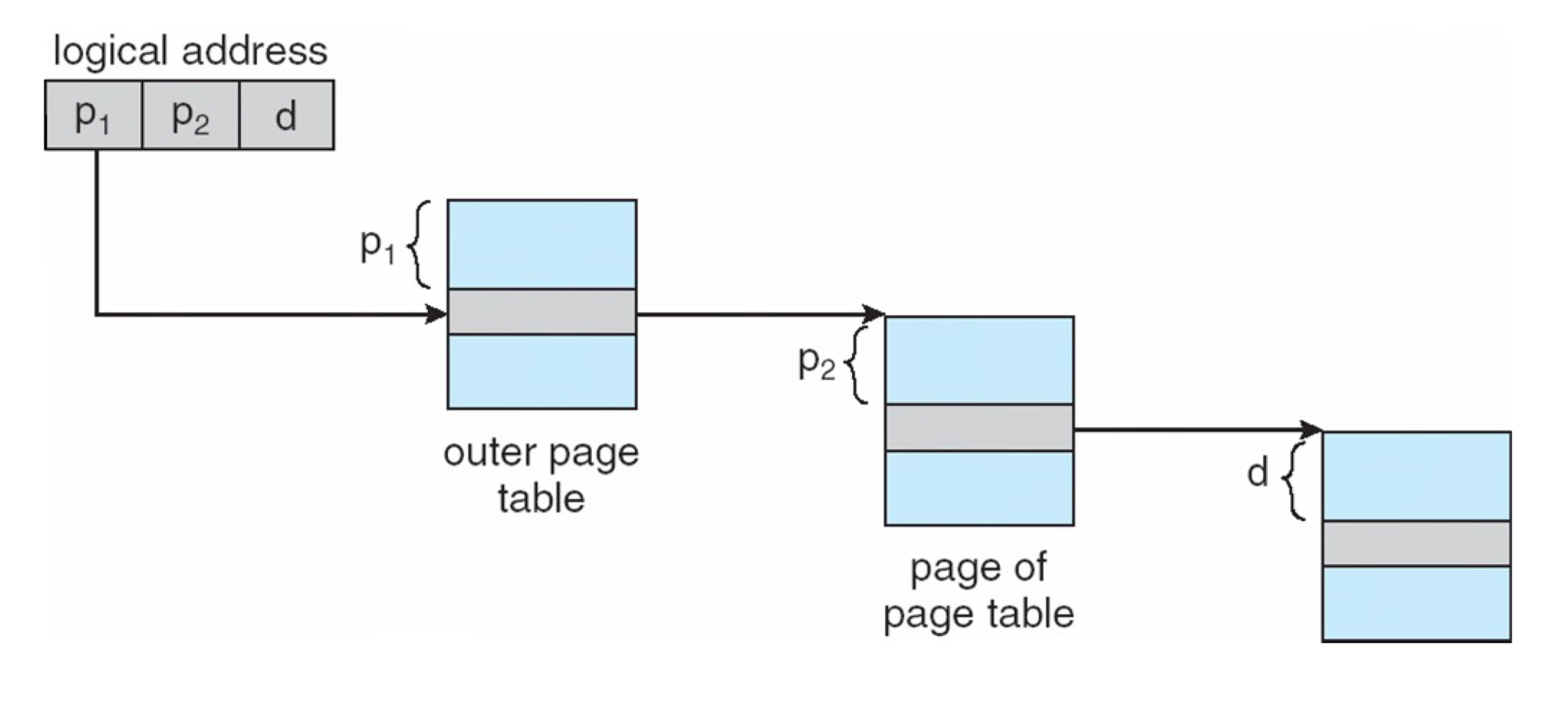
다음과 같이 Two-level page table을 구성할 때, 2^20개의 entry 중 하나의 page만 유효하다면 outer page table 1개(2^10)와 inner page table 1개(2^10)만으로 해당 page를 참조할 수 있습니다. 필요한 entry 크기는 2^10 + 2^10 = 2^11로 2^20보다 훨씬 작아집니다.
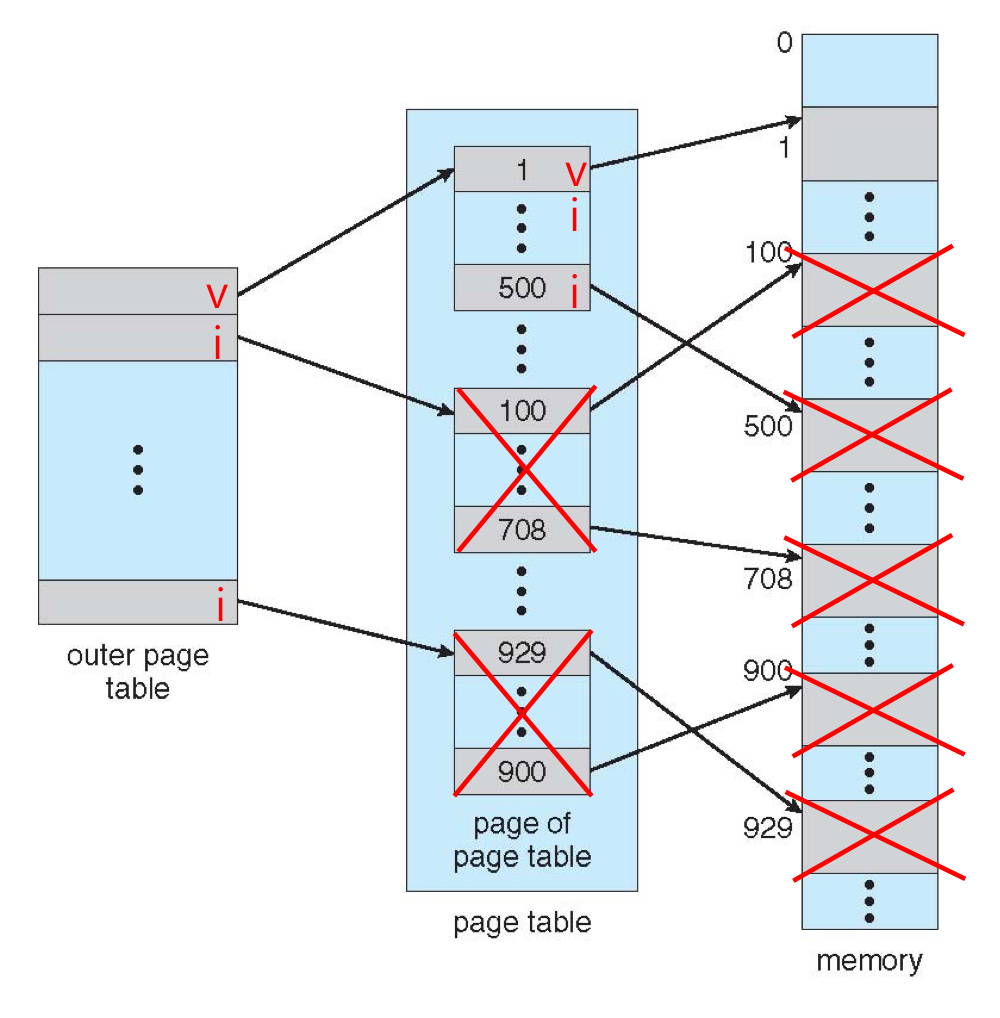
2) Hashed Page Tables
logical address의 page number를 hash function에 넣은 결과로 hash table을 탐색하여 frame number를 찾는 방식입니다. 중복되는 hash function의 결과 값을 갖는 페이지들은 hash table 내에 linked list로 관리됩니다.

3) Inverted Page Table
physical memory의 특정 영역은 한번에 하나의 프로세스 page만 점유하여 사용하게 됩니다. 이러한 특성을 활용하여 frame number를 인덱스로 하고, 이에 대응되는 pid와 page number를 기록하는 frame table을 만드는 방식입니다. 하나의 physical memory에 대한 frame table을 만드는 것이기 때문에 프로세스 별로 따로 page table을 만들어 관리할 필요가 없습니다.

Segmentaion
logcal address를 code segment, data, heap, stack 등 용도 별로 나누고 해당 segemnt를 physical memory에 할당하는 방식입니다. 각 segment는 크기가 모두 다르고, 따라서 limit 와 base address를 할당받습니다.

Segmentation의 logical address는 (segement, offset)으로 표현됩니다. CPU에서 특정 segemnt의 offset을 참조하라는 명령을 받으면, segement table에서 limit와 base address를 확인합니다. 만약 offset이 limit를 초과한다면 이는 다른 프로세스의 범위를 침범하는 것이므로 addressing error를 발생시킵니다. offset이 정상 범위 내에 있다면, offset에 base address 를 더해 physical memory에 접근할 수 있습니다.
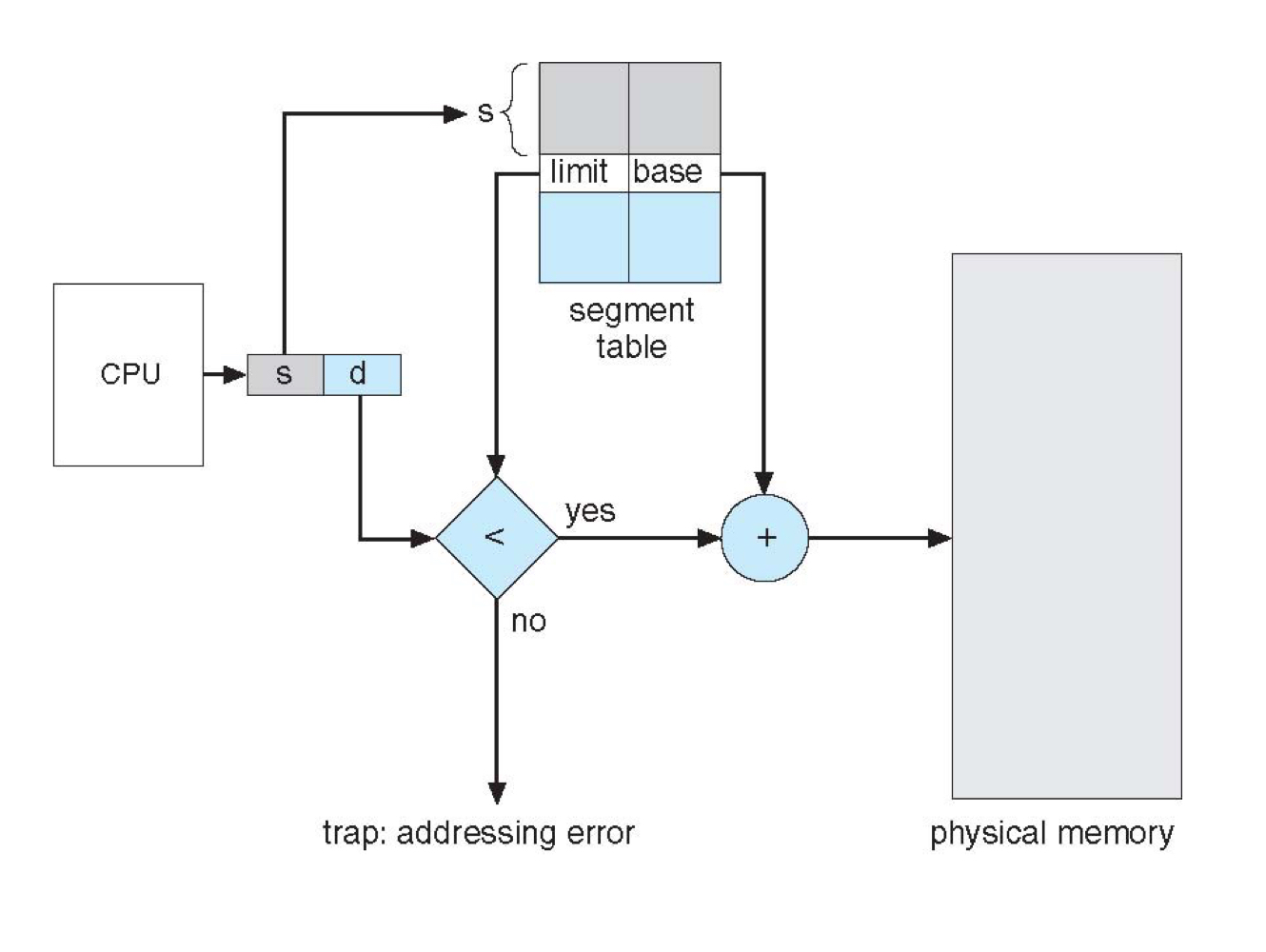
Segmentaion은 logical memory를 의미 단위로 구분하기 때문에 locality가 향상됩니다. 일반적으로 page 의 크기보다 sement의 크기가 더 크기 때문에 segment table entry 개수는 page table entry 수보다 적습니다. 하지만 segment 마다 크기가 다르고, 이를 physical memory에 연속적으로 할당하기 때문에 External fragment가 발생한다는 단점이 있습니다.
Paged segments(Segmentation with paging)
결과적으로, 현재 OS 시스템에서는 Segement와 Page를 혼합하여 Hybrid 형태로 사용하고 있습니다. logical memory를 의미 단위의 segment로 나누고, segment 내부를 다시 일정 크기의 page로 나누어 locality는 높이고 External fragment는 제거합니다.
'Computer Basics > OS' 카테고리의 다른 글
| 메모리 관리_Demand paging, Page replacement algorithms(FCFS, LRU, LRU Approximation(NRU), LFU, MFU) (0) | 2022.06.21 |
|---|---|
| 메모리 관리_Address binding(Compile time, Load time, Execution time) (0) | 2022.06.16 |
| Deadlock_Deadlock의 발생 조건 (0) | 2022.06.15 |
| 동기화_High level Synchronizations Tools(Semaphore, Mutex, Monitor) (0) | 2022.06.15 |
| 동기화_Low Level Synchronization Tools(Spin Lock, Disabling interrupts) (0) | 2022.06.14 |
댓글